import torch
import torch.nn as nn
import math
class InputEmbeddings(nn.Module):
def __init__(self, vocab_size: int , d_model: int):
super.__init__()
self.vocab_size = vocab_size
self.d_model=d_model
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x)*math.sqrt(self.d_model)
class PositionEmbedding(nn.Module):
def __init__(self, Seq_len:int, d_model:int, dropout:float)-> None:
super().__init__()
self.Seq_len=Seq_len
self.d_model=d_model
self.dropout=nn.Dropout(dropout)
pe=torch.zeros(self.Seq_len,self.d_model)
position = torch.arange(0,self.Seq_len,dtype=torch.float).unsqueeze(1)
# apply sin to 2i
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model))
pe[:,0::2] = torch.sin(position * div_term)
pe[:,1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe",pe)
def forward(self,x):
x = x + (self.pe[:,:x.shape[1],:]).requires_grad_(False)
return self.dropout(x)
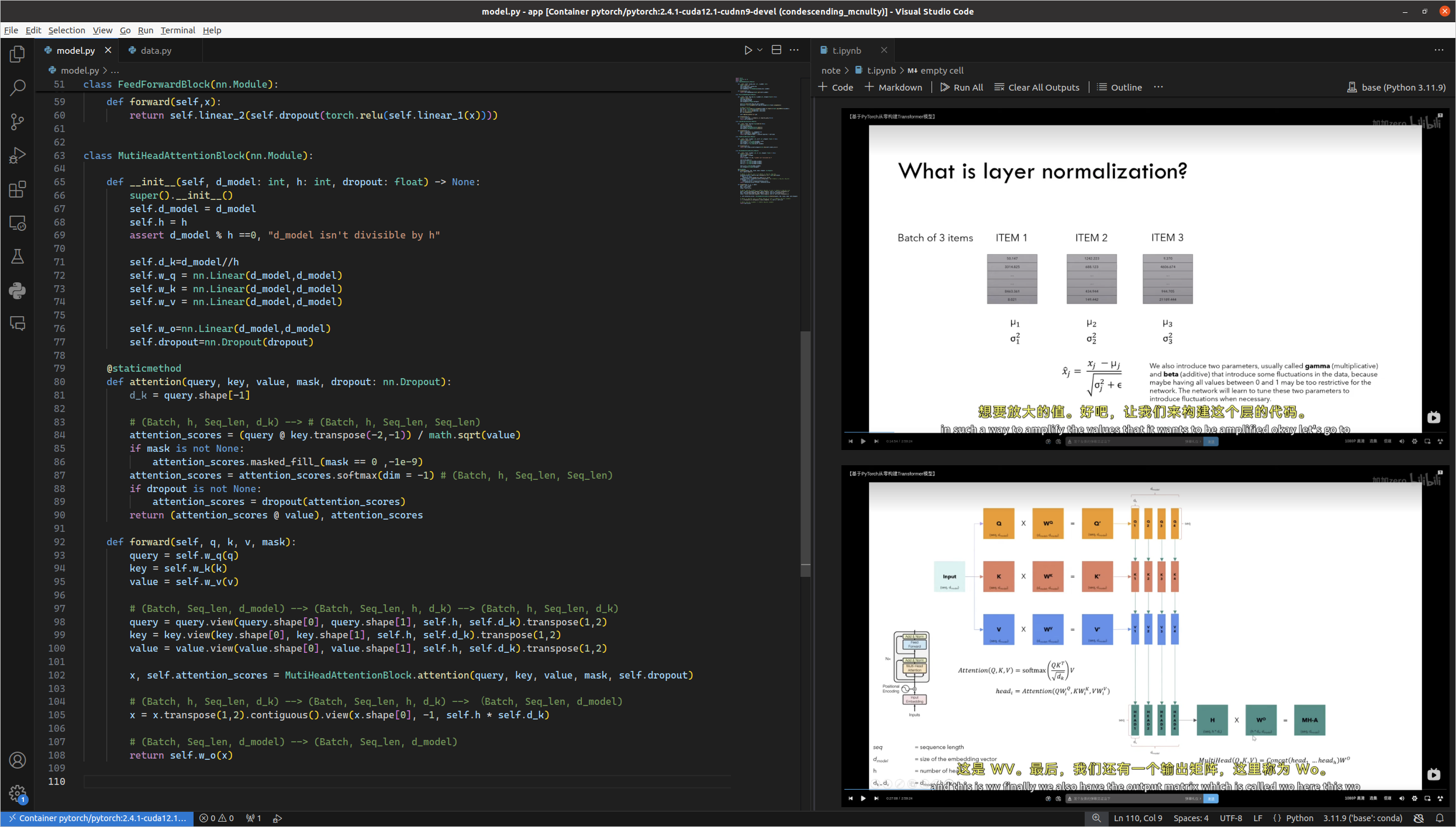
class LayerNormalization(nn.Module):
def __init__(self, epsilon:float=10**-6)->None:
super().__init__()
self.epsilon=epsilon
self.alpha=nn.Parameter(torch.ones(1))
self.bias=nn.Parameter(torch.zeros(1))
def forward(self,x):
mean = x.mean(dim = -1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.alpha*(x-mean) / (std+self.epsilon) + self.bias
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int ,dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self,x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h ==0, "d_model isn't divisible by h"
self.d_k=d_model//h
self.w_q = nn.Linear(d_model,d_model)
self.w_k = nn.Linear(d_model,d_model)
self.w_v = nn.Linear(d_model,d_model)
self.w_o=nn.Linear(d_model,d_model)
self.dropout=nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, mask, dropout: nn.Dropout):
d_k = query.shape[-1]
# (Batch, h, Seq_len, d_k) --> # (Batch, h, Seq_len, Seq_len)
attention_scores = (query @ key.transpose(-2,-1)) / math.sqrt(value)
if mask is not None:
attention_scores.masked_fill_(mask == 0 ,-1e-9)
attention_scores = attention_scores.softmax(dim = -1) # (Batch, h, Seq_len, Seq_len)
if dropout is not None:
attention_scores = dropout(attention_scores)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
# (Batch, Seq_len, d_model) --> (Batch, Seq_len, h, d_k) --> (Batch, h, Seq_len, d_k)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1,2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1,2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1,2)
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
# (Batch, h, Seq_len, d_k) --> (Batch, Seq_len, h, d_k) --> (Batch, Seq_len, d_model)
x = x.transpose(1,2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# (Batch, Seq_len, d_model) --> (Batch, Seq_len, d_model)
return self.w_o(x)
class ResidualConnection(nn.Module):
def __init__(self, dropout: float) -> None:
super().__init__()
self.dropout=nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout), ResidualConnection(dropout)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
super.__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, mask):
for layer in self.layers:
x=layer(x,mask)
return self.norm(x)
class DecoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock,
cross_attention_block: MultiHeadAttentionBlock,
feed_forward_block: FeedForwardBlock,
dropout: float) -> None:
super.__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout),ResidualConnection(dropout),ResidualConnection(dropout)])
def forward(self, x, encoder_output, src_mask, tag_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tag_mask))
x = self.residual_connections[1](x, lambda x: self.self_attention_block(x, encoder_output, encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int) -> None:
super.__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return torch.log_softmax(self.proj(x), dim=-1)
class Transformer(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbeddings, tgt_embed: InputEmbeddings,
src_pos: PositionEmbedding, tgt_pos: PositionEmbedding, projection_layer: ProjectionLayer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encoder(self, src, src_mask):
return self.encoder(self.src_pos(self.src_embed(src)), src_mask)
def decoder(self, tgt, encoder_output, src_mask, tgt_mask):
return self.decoder(self.tgt_pos(self.tgt_embed(tgt)), encoder_output, src_mask, tgt_mask)
def project(self, x):
return self.projection_layer(x)
class build_transformer(nn.Module):
def __init__(self, src_vocab_size: int,
tgt_vocab_size: int,
src_seq_len: int,
tgt_seq_len: int,
d_model: int = 512,
N: int =6,
h: int=8,
d_ff: int=2048,
dropout: float=0.1
) -> Transformer:
super().__init__()
src_embed = InputEmbeddings(src_vocab_size, d_model)
tgt_embed = InputEmbeddings(tgt_vocab_size, d_model)
src_pos = PositionEmbedding(src_seq_len, d_model, dropout)
tgt_pos = PositionEmbedding(tgt_seq_len, d_model, dropout)
encoder_blocks = []
for _ in range(N):
encoder_blocks.append(EncoderBlock(MultiHeadAttentionBlock(d_model, h, dropout),
FeedForwardBlock(d_model, d_ff, dropout),
dropout))
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder_blocks = []
for _ in range(N):
decoder_blocks.append(DecoderBlock(MultiHeadAttentionBlock(d_model, h, dropout),
MultiHeadAttentionBlock(d_model, h, dropout),
FeedForwardBlock(d_model, d_ff, dropout),
dropout))
decoder = Decoder(nn.ModuleList(decoder_blocks))
projection_layer = ProjectionLayer(d_model, tgt_vocab_size)
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer
import torch
import torch.nn as nn
import math
class InputEmbeddings(nn.Module):
def __init__(self, vocab_size: int , d_model: int):
super.__init__()
self.vocab_size = vocab_size
self.d_model=d_model
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x)*math.sqrt(self.d_model)
class PositionEmbedding(nn.Module):
def __init__(self, Seq_len:int, d_model:int, dropout:float)-> None:
super().__init__()
self.Seq_len=Seq_len
self.d_model=d_model
self.dropout=nn.Dropout(dropout)
pe=torch.zeros(self.Seq_len,self.d_model)
position = torch.arange(0,self.Seq_len,dtype=torch.float).unsqueeze(1)
# apply sin to 2i
div_term = torch.exp(torch.arange(0,d_model,2).float()*(-math.log(10000.0)/d_model))
pe[:,0::2] = torch.sin(position * div_term)
pe[:,1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe",pe)
def forward(self,x):
x = x + (self.pe[:,:x.shape[1],:]).requires_grad_(False)
return self.dropout(x)
class LayerNormalization(nn.Module):
def __init__(self, epsilon:float=10**-6)->None:
super().__init__()
self.epsilon=epsilon
self.alpha=nn.Parameter(torch.ones(1))
self.bias=nn.Parameter(torch.zeros(1))
def forward(self,x):
mean = x.mean(dim = -1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.alpha*(x-mean) / (std+self.epsilon) + self.bias
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int ,dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self,x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.h = h
assert d_model % h ==0, "d_model isn't divisible by h"
self.d_k=d_model//h
self.w_q = nn.Linear(d_model,d_model)
self.w_k = nn.Linear(d_model,d_model)
self.w_v = nn.Linear(d_model,d_model)
self.w_o=nn.Linear(d_model,d_model)
self.dropout=nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, mask, dropout: nn.Dropout):
d_k = query.shape[-1]
# (Batch, h, Seq_len, d_k) --> # (Batch, h, Seq_len, Seq_len)
attention_scores = (query @ key.transpose(-2,-1)) / math.sqrt(value)
if mask is not None:
attention_scores.masked_fill_(mask == 0 ,-1e-9)
attention_scores = attention_scores.softmax(dim = -1) # (Batch, h, Seq_len, Seq_len)
if dropout is not None:
attention_scores = dropout(attention_scores)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
# (Batch, Seq_len, d_model) --> (Batch, Seq_len, h, d_k) --> (Batch, h, Seq_len, d_k)
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1,2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1,2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1,2)
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, mask, self.dropout)
# (Batch, h, Seq_len, d_k) --> (Batch, Seq_len, h, d_k) --> (Batch, Seq_len, d_model)
x = x.transpose(1,2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# (Batch, Seq_len, d_model) --> (Batch, Seq_len, d_model)
return self.w_o(x)
class ResidualConnection(nn.Module):
def __init__(self, dropout: float) -> None:
super().__init__()
self.dropout=nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout), ResidualConnection(dropout)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x
class Encoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
super.__init__()
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, mask):
for layer in self.layers:
x=layer(x,mask)
return self.norm(x)
class DecoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock,
cross_attention_block: MultiHeadAttentionBlock,
feed_forward_block: FeedForwardBlock,
dropout: float) -> None:
super.__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout),ResidualConnection(dropout),ResidualConnection(dropout)])
def forward(self, x, encoder_output, src_mask, tag_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tag_mask))
x = self.residual_connections[1](x, lambda x: self.self_attention_block(x, encoder_output, encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x
class Decoder(nn.Module):
def __init__(self, layers: nn.ModuleList) -> None:
self.layers = layers
self.norm = LayerNormalization()
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return self.norm(x)
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int) -> None:
super.__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return torch.log_softmax(self.proj(x), dim=-1)
class Transformer(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbeddings, tgt_embed: InputEmbeddings,
src_pos: PositionEmbedding, tgt_pos: PositionEmbedding, projection_layer: ProjectionLayer):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encoder(self, src, src_mask):
return self.encoder(self.src_pos(self.src_embed(src)), src_mask)
def decoder(self, tgt, encoder_output, src_mask, tgt_mask):
return self.decoder(self.tgt_pos(self.tgt_embed(tgt)), encoder_output, src_mask, tgt_mask)
def project(self, x):
return self.projection_layer(x)
class build_transformer(nn.Module):
def __init__(self, src_vocab_size: int,
tgt_vocab_size: int,
src_seq_len: int,
tgt_seq_len: int,
d_model: int = 512,
N: int =6,
h: int=8,
d_ff: int=2048,
dropout: float=0.1
) -> Transformer:
super().__init__()
src_embed = InputEmbeddings(src_vocab_size, d_model)
tgt_embed = InputEmbeddings(tgt_vocab_size, d_model)
src_pos = PositionEmbedding(src_seq_len, d_model, dropout)
tgt_pos = PositionEmbedding(tgt_seq_len, d_model, dropout)
encoder_blocks = []
for _ in range(N):
encoder_blocks.append(EncoderBlock(MultiHeadAttentionBlock(d_model, h, dropout),
FeedForwardBlock(d_model, d_ff, dropout),
dropout))
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder_blocks = []
for _ in range(N):
decoder_blocks.append(DecoderBlock(MultiHeadAttentionBlock(d_model, h, dropout),
MultiHeadAttentionBlock(d_model, h, dropout),
FeedForwardBlock(d_model, d_ff, dropout),
dropout))
decoder = Decoder(nn.ModuleList(decoder_blocks))
projection_layer = ProjectionLayer(d_model, tgt_vocab_size)
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer